# 任务管理
# 任务机制
任务(task)是 XiUOS 中处理器使用权分配的最小单位。每个任务有自己的程序栈与寄存器上下文,在多处理器平台上可以互不干扰地同时运行,但单个处理器上任意时刻只能有一个任务在运行。用户可以使用 XiUOS 提供的接口创建任意数量的任务。内核会对系统中的所有任务按照一定策略(抢占式优先级或先来先服务)进行调度,最大限度地利用处理器资源。
# 任务状态
XiUOS 中的任务在任意时刻都处于就绪(ready)、运行(running)、阻塞/挂起(suspend)、退出(close)四种状态之一。状态之间的变化关系如下图所示。
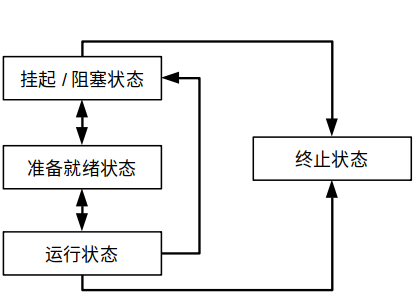
- 任务在创建完成后会进入就绪状态并被加入就绪队列等待内核 CPU 调度
- 当任务被调度开始运行时,任务会进入运行状态
- 若任务在运行过程中被更高优先级的任务抢占,则被抢占的任务会回到就绪队列并再次进入就绪状态
- 当任务在运行过程中申请资源失败时,任务会被挂起并进入挂起状态,并在所申请资源能够被满足时回到就绪状态
- 当任务执行完成,即从入口函数返回时,会进入终止状态,并由内核回收其相关资源
# 任务调度
任务调度即从系统就绪队列中按一定策略选择某一任务,使其进入运行状态的过程。XiUOS 支持以下调度方式:
- 抢占式优先级调度,即在创建任务时,用户可以指定任务的优先级,内核总是选取就绪队列中优先级最高的任务。当新创建的任务优先级高于正在运行的任务的优先级时,当前运行任务的CPU使用权会被抢占。若就绪队列中最高优先级任务有多个,则这些任务会按时间片轮转方式交替运行。
- 先来先服务(FIFO)调度,即任务按照被创建的顺序依次被执行。当一个任务运行完成后,系统才会让下一个任务开始运行。
- 时间片轮转(RR)调度,即任务按照分配的时间片执行,时间片结束,调度一个新的就绪任务执行,当前任务重新就绪,等待下一次的调度。
# 任务结构定义
每一个任务在内核中都有一个TaskDescriptor描述符,其结构体定义如下:
struct TaskDescriptor
{
void *stack_point;
TaskDyncSchedMembeType task_dync_sched_member;
TaskBaseInfoType task_base_info;
#ifdef ARCH_SMP
TaskSmpInfoType task_smp_info;
#endif
#if defined(KERNEL_EVENT)
uint32 event_id_trigger:29;
uint32 event_mode:3;
#endif
x_err_t exstatus;
DoubleLinklistType link;
struct IdNode id;
struct KTaskDone *Done;
};
其中,stack_point 指向任务堆栈的起始地址,task_dync_sched_member 包含与任务调度相关的信息,task_base_info 记录任务的基本信息,task_smp_info 统计与多处理器相关的信息,event_id_trigger / event_mode 用于实现事件集机制(详见任务通信),exstatus为任务调用内核接口时最近的错误码,即用户线程在使用内核接口时可能会执行失败,此时内核接口返回-1,具体的错误码被保存在成员变量exstatus中,且在下一次调用内核接口失败时被覆盖,link 用于组织内核中所有的任务。id 用于表示一个线程,Done提供所有的线程的操作函数,各复合成员的详细定义如下。
- struct TaskDyncSchedMember
struct TaskDyncSchedMember {
uint8 stat;
uint8 advance_cnt;
uint8 cur_prio;
ubase origin_timeslice;
ubase rest_timeslice;
#ifdef SEPARATE_COMPILE
uint8 isolation_flag;
void *isolation;
uint8 isolation_status;
#endif
union {
DoubleLinklistType sched_link;
AvlNodeType sched_avl;
};
#if KTASK_PRIORITY_MAX > 32
uint8 bitmap_offset;
uint8 bitmap_row;
#endif
uint32 bitmap_column;
delay_t delay;
};
#define KTASK_INIT 0x00
#define KTASK_READY 0x01
#define KTASK_SUSPEND 0x02
#define KTASK_RUNNING 0x03
#define KTASK_CLOSE 0x04
TaskDyncSchedMember结构用于记录与调度相关的信息。stat记录任务的当前状态,可以为初始化(KTASK_INIT)挂起(KTASK_SUSPEND)、就绪(KTASK_READY)、运行(KTASK_RUNNING)或退出(KTASK_CLOSE)。advance_cnt表示在配置成短作业预先调度时优先处理的时间片周期个数。cur_prio表示任务当前的优先级,用于优先级反转,该优先级可以高于任务创建时配置的优先级。origin_timeslice表示在时间片轮转调度时,任务每次运行的时间片。isolation_flag变量和指针isolation支持地址空间隔离,isolation_status用于标志内核服务的过程(1表示进入内核服务上下文)。sched_link和sched_avl构成的联合体为就绪队列节点,XiUOS中就绪队列可以组织为双链表(sched_link)或平衡二叉树(sched_avl)。task_timer为任务睡眠的计数器。
- struct TaskBaseInfo
struct TaskBaseInfo {
char name[NAME_NUM_MAX];
void *func_entry;
void *func_param;
uint8 origin_prio;
uint32 stack_depth;
void *stack_start;
};
TaskBaseInfo结构记录了任务的基本属性,包括任务的名称(name)、入口函数(func_entry)和参数(func_param)、栈大小(stack_depth)、初始优先级(origin_prio)。
- struct TaskSmpInfo
struct TaskSmpInfo {
uint8 combined_coreid;
uint8 running_coreid;
uint16 critical_lock_cnt;
};
TaskSmpInfo结构包含多处理器相关的信息,其成员分别表示该任务绑定的CPU ID与正在运行的CPU ID。
# 任务函数接口
struct utask
{
char name[NAME_NUM_MAX];
void *func_entry;
void *func_param;
uint32 stack_size;
uint8 prio;
};
typedef struct utask UtaskType;
int32_t UserTaskCreate(UtaskType task);
该函数用于用户态的任务创建。任务的各个属性由utask结构表示,包括任务的名称、入口函数及参数、栈大小和优先级,在调用该函数时需要传入该结构的实例用于配置任务属性。任务创建成功后,内核会为其分配指定大小的栈及其他结构(如struct TaskDescriptor),并返回任务id。
| 参数 | 描述 |
|---|---|
| task | 任务配置属性 |
x_err_t UserTaskStartup(int32_t id);
该函数用于就绪一个任务,交由调度器开始调度执行。
| 参数 | 描述 |
|---|---|
| id | 待就绪的任务ID |
x_err_t UserTaskDelete(int32_t id);
该函数用于删除一个任务,强制其进入退出状态。若删除成功则返回EOK,否则返回-ERROR。
| 参数 | 描述 |
|---|---|
| id | 待删除的任务ID |
x_err_t UserTaskCoreCombine(int32_t id,uint8_t core_id);
该函数用于将任务绑定至指定的处理器上。若绑定成功则返回EOK,否则返回-ERROR。
| 参数 | 描述 |
|---|---|
| id | 待绑定的任务ID |
| core_id | 待绑定的处理器ID |
x_err_t UserTaskCoreUnCombine(int32_t id);
该函数用于解除任务与处理器的绑定。若解除成功则返回EOK,否则返回-ERROR。
| 参数 | 描述 |
|---|---|
| id | 待解除绑定的任务ID |
x_err_t UserTaskDelay(int32_t ms);
该函数用于将当前任务挂起一定时间,单位为ms。挂起时间结束后,任务会进入就绪状态,等待系统调用。
| 参数 | 描述 |
|---|---|
| ms | 任务挂起时间,单位为ms |
# 任务通信
XiUOS 提供多种任务间通信机制,包括消息队列、信号量、互斥量与事件集。
# 消息队列
消息队列(message queue)提供可供多个任务读或写的消息缓冲区,其中消息指固定长度的任意数据块。消息队列的容量有限。当消息队列满时,向消息队列写入的任务会被挂起;当消息队列空时,从消息队列读取的任务会被挂起。
# 消息队列结构定义
struct MsgQueue
{
struct IdNode id;
void *msg_buf;
uint16 index;
uint16 num_msgs;
uint16 each_len;
uint16 max_msgs;
DoubleLinklistType send_pend_list;
DoubleLinklistType recv_pend_list;
DoubleLinklistType link;
struct MsgQueueDone *Done;
};
| 成员 | 描述 |
|---|---|
| id | 消息队列ID,用于唯一标识一个消息队列 |
| msg_buf | 用于存储消息的缓冲区的首地址 |
| index | 当前缓冲区中第一个消息的序号 |
| num_msgs | 当前缓冲区中的消息数量 |
| each_len | 每条消息的大小,单位为字节 |
| max_msgs | 缓冲区中最多能存放的消息数量 |
| send_pend_list | 被挂起的发送任务链表 |
| recv_pend_list | 被挂起的接收任务链表 |
| link | 系统中所有消息队列构成的链表 |
| ops | 消息队列的操作函数集 |
# 消息队列函数接口
int32_t UserMsgQueueCreate(size_t msg_size, size_t max_msgs);
该函数用于创建一个消息队列。创建成功后,新的消息队列会被加入内核的消息队列管理链表,并返回该消息队列的ID,ID默认范围0-255,可配置。
| 参数 | 描述 |
|---|---|
| msg_size | 每条消息的长度,单位为字节 |
| max_msgs | 缓冲区中最多存放的消息数量 |
x_err_t UserMsgQueueDelete(int32_t mq);
该函数用于删除一个已创建的消息队列。
| 参数 | 描述 |
|---|---|
| mq | 待删除的消息队列ID |
x_err_t UserMsgQueueSendwait(int32_t mq, const void *buffer, size_t size, int32_t wait_time);
该函数用于向消息队列发送一个消息。若消息发送成功则返回EOK,若不成功(等待超时)则返回-ETIMEOUT。
| 参数 | 描述 |
|---|---|
| mq | 目标消息队列ID |
| buffer | 消息数据首地址 |
| size | 消息长度 |
| wait_time | 等待时间上限,单位ms;若为0,则不等待 |
x_err_t UserMsgQueueSend(int32_t mq, const void *buffer, size_t size);
该函数用于向消息队列发送一个消息。若消息发送成功则返回EOK,若不成功则返回-ETIMEOUT。
| 参数 | 描述 |
|---|---|
| mq | 目标消息队列ID |
| buffer | 消息数据首地址 |
| size | 消息长度 |
x_err_t UserMsgQueueUrgentSend(int32_t mq, const void *buffer, size_t size);
该函数用于向消息队列优先发送一个消息。若消息发送成功则返回EOK,若不成功(等待超时)则返回-ETIMEOUT。
| 参数 | 描述 |
|---|---|
| mq | 目标消息队列ID |
| buffer | 消息数据首地址 |
| size | 消息长度 |
x_err_t UserMsgQueueRecv(int32_t mq, void *buffer, size_t size,int32_t wait_time);
该函数用于从消息队列接收一个消息。若消息接收成功则返回EOK,若不成功(等待超时)则返回-ETIMEOUT。
| 参数 | 描述 |
|---|---|
| mq | 来源消息队列ID |
| buffer | 用于接收消息数据的缓冲区 |
| size | 缓冲区大小 |
| wait_time | 等待时间上限,单位ms;若为0,则不等待 |
x_err_t UserMsgQueueReinit(int32_t mq);
该函数用于将一个消息队列复位。
| 参数 | 描述 |
|---|---|
| mq | 消息队列ID |
# 信号量
信号量(semaphore)具有一个给定的初值。任务可以获取或释放一个信号量。当任务获取信号量时,信号量的值递减,释放信号量时,信号量的值递增。当信号量的值递减至0时,后续尝试获取信号量的任务会被挂起。当任务释放信号量时,内核会从该信号量的挂起队列上唤醒一个任务。信号量可以实现任务间的同步与互斥。
# 信号量结构定义
struct Semaphore
{
struct IdNode id;
uint16 value;
DoubleLinklistType pend_list;
DoubleLinklistType link;
};
| 成员 | 描述 |
|---|---|
| id | 信号量ID,用于唯一标识一个信号量 |
| value | 信号量的当前值 |
| pend_list | 挂起任务链表 |
| link | 系统中所有信号量构成的链表 |
# 信号量函数接口
sem_t UserSemaphoreCreate(uint16_t val);
该函数用于创建一个信号量。创建成功后,新的信号量会被加入内核的信号量管理链表,并返回该信号量的ID,ID默认范围0-255,可配置。
| 参数 | 描述 |
|---|---|
| val | 信号量的初值 |
x_err_t UserSemaphoreDelete(sem_t sem);
该函数用于删除一个已创建的信号量。
| 参数 | 描述 |
|---|---|
| sem | 待删除的信号量ID |
x_err_t UserSemaphoreObtain(sem_t sem, int32_t wait_time);
该函数用于获取一个信号量。若获取成功则返回EOK,若不成功(等待超时)则返回-ETIMEOUT。
| 参数 | 描述 |
|---|---|
| sem | 欲获取的信号量ID |
| wait_time | 等待时间上限,单位ms;若为0,则不等待 |
x_err_t UserSemaphoreAbandon(sem_t sem);
该函数用于释放一个信号量。
| 参数 | 描述 |
|---|---|
| sem | 待释放的信号量ID |
x_err_t UserSemaphoreSetValue(sem_t sem, uint16_t val);
该函数用于将一个信号量的值进行重置。
| 参数 | 描述 |
|---|---|
| sem | 来源消息队列ID |
| val | 重置的信号量的值 |
# 互斥量
互斥量(mutex)可以视作一个初值为1的信号量,同样有获取和释放操作。互斥量一般用于任务间的互斥。
# 互斥量结构定义
struct Mutex
{
struct IdNode id;
uint16 val;
uint8 recursive_cnt;
uint8 origin_prio;
struct TaskDescriptor *holder;
DoubleLinklistType pend_list;
DoubleLinklistType link;
};
| 成员 | 描述 |
|---|---|
| id | 互斥量ID,用于唯一标识一个互斥量 |
| value | 互斥量的当前值 |
| origin_prio | 持有互斥量的任务的原优先级,用于避免优先级反转 |
| recursive_cnt | 持有互斥量的任务获取互斥量的次数,用于实现递归锁 |
| holder | 持有互斥量的任务 |
| pend_list | 挂起任务链表 |
| link | 系统中所有互斥量构成的链表 |
# 互斥量函数接口
int32_t UserMutexCreate();
该函数用于创建一个互斥量。创建成功后,新的互斥量会被加入内核的互斥量管理链表,并返回该互斥量的ID,ID默认范围0-255,可配置。
void UserMutexDelete(int32_t mutex);
该函数用于删除一个已创建的互斥量。
| 参数 | 描述 |
|---|---|
| mutex | 待删除的互斥量的ID |
int32_t UserMutexObtain(int32_t mutex, int32_t wait_time);
该函数用于获取一个互斥量。若获取成功则返回EOK,若不成功(等待超时)则返回-ETIMEOUT。
| 参数 | 描述 |
|---|---|
| mutex | 欲获取的互斥量的ID |
| wait_time | 等待时间上限,单位ms;若为0,则不等待 |
int32_t UserMutexAbandon(int32_t mutex);
该函数用于释放一个互斥量。
| 参数 | 描述 |
|---|---|
| mutex | 待释放的互斥量的ID |
# 事件集
事件集(event set)允许用户定义一个事件集合,集合中的每个事件都可以被任务触发或等待。任务可以同时等待多个事件,此时等待触发的条件可以配置为 AND 或者 OR :当等待触发条件配置为 AND 时,只有所有被等待的事件均被触发才视作等待结束;当等待触发条件配置为 OR 时,任意一个被等待的事件触发即视作等待结束。使用事件集可以实现多对多的任务间同步与互斥。
# 事件集结构定义
#define EVENT_AND (1 << 0)
#define EVENT_OR (1 << 1)
#define EVENT_AUTOCLEAN (1 << 2)
#define EVENTS(x) (1 << x)
struct Event
{
struct IdNode id;
uint32 options : 3;
uint32 events : 29;
DoubleLinklistType pend_list;
DoubleLinklistType link;
};
| 成员 | 描述 |
|---|---|
| id | 事件集ID,用于唯一标识一个事件集 |
| options | 高3位用于记录事件集属性(等待触发条件、是否自动清空) |
| events | 低29位用于表示至多29个事件 |
| pend_list | 等待任务链表 |
| link | 系统中所有事件集构成的链表 |
# 事件集函数接口
EventIdType UserEventCreate(uint8_t flag);
该函数用于创建一个事件集。flag参数用于配置事件集的属性。可配置的属性有等待触发方式(EVENT_AND 或 EVENT_OR)及等待触发后是否自动清空其他已触发的事件(EVENT_AUTOCLEAN)。创建成功后,新的事件集会被加入内核的事件集管理链表,并返回该事件集的ID,ID默认范围0-255,可配置。
| 参数 | 描述 |
|---|---|
| flag | 事件集配置选项,须在 EVENT_AND 及 EVENT_OR 中指定其一,并可以按位或上 EVENT_AUTOCLEAN |
void UserEventDelete(EventIdType event);
该函数用于删除一个已创建的事件集。
| 参数 | 描述 |
|---|---|
| event | 待删除的事件集的ID |
x_err_t UserEventTrigger(EventIdType event, uint32_t set);
该函数用于触发事件集中的一组事件。
| 参数 | 描述 |
|---|---|
| event | 事件集ID |
| set | 欲触发的事件,其中被置1的位标识被触发的事件 ,可以使用 EVENTS 宏按位或发送事件类型 |
x_err_t UserEventProcess(EventIdType event, uint32_t set, uint8_t option, int32_t wait_time, uint32_t *Recved);
该函数用于等待事件集中的一组事件。若等待成功则返回 EOK,此时若 EVENT_AUTOCLEAN 被打开则事件集中所有已触发事件会被清空;若等待失败(超时)则返回 -ETIMEOUT。
| 参数 | 描述 |
|---|---|
| event | 事件集ID |
| set | 欲等待的事件,其中被置1的位标识被等待的事件,可以使用EVENTS宏按位或接收事件类型 |
| options | 用于记录事件集属性(等待触发条件、是否自动清空) |
| wait_time | 等待时间上限,单位 ms;若为0,则不等待 |
| Recved | 用于记录已经被处理完成的事件 |
x_err_t UserEventReinit(EventIdType event);
该函数用于将一个事件的值进行重置。
| 参数 | 描述 |
|---|---|
| event | 来源消息队列ID |
# 任务隔离
# 背景及动机
XiUOS 是一个支持多任务的操作系统,对任务的数量没有限制。在 XiUOS 中,每个任务都需要自己的堆栈,同时也可能会动态申请内存资源。任务在运行过程中发生内存溢出是 RTOS 系统中最常见的问题,所以限制任务的内存空间访问是保证 RTOS 稳定运行的关键。
ARM 和 RISC-V 在体系架构上都提供了内存访问的保护功能,可以通过对特定寄存器的硬编程实现对指定内存区域访问权限的设置。然而,现有的大多数物联网操作系统并没有使用体系结构提供的内存保护功能来对任务运行的地址空间进行隔离保护。XiUOS 充分考虑任务运行的安全问题,在不影响任务正常执行的情况下,对每个任务所允许访问的内存地址空间进行限制。除此之外,任务在动态申请内存、释放内存、内存共享时,XiUOS也将提供隔离服务。
XiUOS 任务隔离的总体设计思想是将物理内存地址空间划分为信任地址空间和非信任地址空间。XiUOS 的内核任务运行在信任地址空间,可以访问所有信任地址空间和非信任地址空间;XiUOS 的用户程序运行在非信任地址空间,通过”内核服务表“的方式访问内核任务提供的功能。
# 内核服务表
ARM 和 RISC-V 在体系架构上支持机器在特权模式和非特权模式之间转换。XiUOS 的内核任务运行在特权模式下,可以访问体系结构支持的、可编程的所有硬件资源。XiUOS 的用户程序运行在非特权模式下,对硬件资源的访问权限是受限制的。为了实现用户程序受限的硬件资源访问以及内核任务提供的其他功能,XiUOS 的内核为用户程序提供一组服务接口来满足应用程序的这些需求,这一组内核服务接口称为内核服务表。应用程序访问内核服务接口的流程如下:
- 应用程序执行异常调用指令并指定相应内核服务号和参数;
- 通过软中断指令产生一个调用异常,之后 CPU 切换到特权模式并强制执行异常处理流程,异常处理流程提取内核服务号和参数,并将服务号作为索引;
- 根据索引从内核服务表中查找对应的内核服务接口;
- 在特权模式下,执行所需的内核服务,完成后切换回非特权模式继续执行。
# 任务隔离表
在 XiUOS 中,任务描述符 TaskDescriptor 管理系统的任务,其中包含了任务优先级、任务名称、任务状态等信息。为了管理任务可访问的内存空间,TaskDescriptor 描述符在 TaskDyncSchedMember 子结构中增加任务隔离标志位 isolation_flag 和任务隔离成员isolation、isolation_status, 其定义如下:
struct TaskDyncSchedMember
{
…
#ifdef SEPARATE_COMPILE
uint8 isolation_flag;
void *isolation;
uint8 isolation_status;
#endif
…
};
用户程序运行在非信任地址空间,默认开启隔离机制。在用户程序对应的任务被创建时,任务隔离标志位 isolation_flag 被置为1,其允许访问的地址空间范围由 isolation_table 指针所指定。isolation_table 包含了任务可访问的多个内存地址空间,每个内存地址空间用一个 isolation_region 数据结构来描述,这个数据结构包括一段连续的地址空间范围和访问权限,其具体结构取决于体系架构提供的内存保护功能,如 ARM 提供的 MPU 和 RISC-V 提供的 PMP 功能。isolation_region 的定义如下:
#if defined(TASK_ISOLATION)
typedef struct isolation_region
{
#ifdefined (XS_RISCV32)
xs_uint8 region_cfg;
xs_uint32 region_addr;
#elif defined (XS_RISCV64)
xs_uint8 region_cfg;
xs_uint64 region_addr;
#elif defined (XS_ARM32)
xs_uint32 region_cfg;
xs_uint32 region_addr;
#endif
}isolation_region;
#endif
# 隔离机制
- 任务内存结构分布及 isolation_region
XiUOS 中的任务在编译链接后形成Linux通用的ELF文件结构,其中包括.code、.data、.bss等段。在任务加载过程中,.code、.data、.bss会被加载到对应的内存段中。在创建任务时,先判断任务类型,UserTaskCreate用于创建任务,其中 isolation_flag 标志位会被置为1。当为任务分配好栈空间后,isolation_table 中为.code、.data、.bss 等段分别创建一个 isolation_region,并设置对应的地址范围和访问权限,如.code段对应的 isolation_region 为读和执行权限,.data 段对应的 isolation_region 为只读权限,.bss 段和栈对应的 isolation_region 为读写权限。 - 任务切换时的隔离
在 XiUOS 中,多个任务共享有限个 CPU 核,采用优先级加时间片的调度方式,当一个任务时间片耗尽或者主动让出 CPU 的使用权时,内核调度程序负责保存当前任务的上下文信息,并从等待队列中挑选下一个就绪任务,恢复其上下文信息,并允许其获取 CPU 的使用权。为了保证每个任务只能访问自己的内存空间,内核调度程序在恢复任务上下文时,会先根据 isolation_flag 标志判断该任务是否为用户程序,如果为用户程序,则当前 CPU 核在运行该任务时,只允许访问本任务 isolation_table 中定义的内存区域,对于其它区域没有访问权限。 - 动态申请/释放内存时的隔离
XiUOS 的任务通过 malloc/free 等内核服务接口来动态申请和释放内存空间,并能根据用户任务申请和释放的内存地址更新任务隔离表。当用户程序通过 malloc 等内核服务接口向内核申请指定大小的内存空间时,系统会在用户程序对应的任务中增加对内存空间的访问权限,同时将更新后的任务隔离表加载到内存保护单元配置寄存器中,使其生效。当用户程序通过 free 等内核服务接口向内核释放指定大小的内存空间时,系统会在用户程序对应的任务隔离表中清除对这段内存空间的访问权限,同时加载更新后的任务隔离表到内存保护单元寄存器中,使其生效。
此外,XiUOS 还支持共享内存的任务隔离,其基本思路同动态内存申请/释放时相同。进一步地,当用户程序因为某种原因试图访问没有权限的内存空间时,CPU 会产生一个访问错误的异常,并进入内核服务接口的异常处理流程,在这个流程中会将该任务直接杀死并回收任务资源。 - RISC-V 64架构任务隔离
大部分 RISC-V 架构的 CPU 拥有特权模式和非特权模式。这两种模式都为 CPU 核提供了物理内存保护(PMP,Physical Memory Protection)功能。通过编程 PMP,可以为指定大小的内存区域设置读、写、执行等访问权限。PMP 包括 8~16 组配置寄存器和地址寄存器,一组配置寄存器和地址寄存器称为一个 PMP entry,PMP entry 对应之前定义的 isolation_region,用于标识一段内存地址空间的访问权限。 对于一个正在运行用户任务,其isolation_table的内容大致如下:
isolation_table[16] =
{
{ //.code
.region_cfg = __PMP_REGION_CFG( 0, // L=0,用户任务遵守RWX指定的权限,内核任务拥有全部权限,
.region_addr = __PMP_REGION_ADDR(text_start_addr,region_start_addr_size);
},
{ //.data
.region_cfg = __PMP_REGION_CFG( 0, //L=0,用户任务遵守RWX指定的权限,内核任务拥有全部权限
.region_addr = __PMP_REGION_ADDR(data_start_addr,region_start_addr_size);
},
{ //.bss段
.region_cfg = __PMP_REGION_CFG( 0, //L=0,用户任务遵守RWX指定的权限,内核任务拥有全部权限
.region_addr = __PMP_REGION_ADDR(bss_start_addr,region_start_addr_size);
},
{ // stack
.region_cfg = __PMP_REGIONP_CFG( 0,//L=0,用户任务遵守RWX指定的权限,内核任务拥有全部权限
.region_addr = __PMP_REGION_ADDR(stack_start_addr,region_start_addr_size);
},
…
};
相关PMP操作的接口如下:
// isolation_table增加一个region
PMP_add_region(isolation_region *isolation_table, void *region_address, xs_size_t size, int flag);
// isolation_table增加清除一个region
PMP_clear_region(isolation_region *isolation_table, void *region_address,xs_size_t size);
// 将isolation_table加载到PMP中
PMP_load(isolation_region *isolation_table, xs_uint8 coreid);
- ARM-32 架构任务隔离
ARM32 的 handler mode 和 thread mode 分别对应特权模式和非特权模式。ARM32 架构的 MPU 单元可以对内存地址空间的访问权限进行设置,从而实现任务地址空间的隔离访问。MPU 通过将内存空间划分为多个 “region” 进行权限设置,一个 region 就是一段连续的地址空间,对应之前定义的 isolation_region,一般 MPU 支持设置8~16个regions。在启用MPU后,程序就无法访问定义之外的地址区间,也不得访问未经授权的region,否则,将会触发内存访问错误。对于正在运的行用户任务,ARM32 的 isolation_table 的内容同 RISC-V 架构基本相同。
相关MPU的操作接口如下:
// isolation_table增加一个region
MPU_add_region(isolation_region *isolation_table, void *region_address, xs_size_t size, int flag);
// isolation_table增加清除一个region
MPU_clear_region(isolation_region *isolation_table, void *region_address, xs_size_t size);
// 将isolation_table加载到MPU中
MPU_load(isolation_region *isolation_table, xs_uint8 coreid);
# 性能测试
# 概述
下面分别测试XiUOS系统运行在基于 ARM 和 RISC-V 不同处理器的开发板时,任务的切换时间。
# 基于 ARM 处理器的任务切换性能测试
# 测试方法
为了测试系统的任务切换时间,考虑使用GPIO管脚进行测试,将GPIO在任务切换开始和结束时分别置为高电平和低电平。
- 配置C13管脚为输出模式,接示波器通道1或2
- 示波器GND和开发板GND共地对接

XiUOS的任务切换函数为宏定义DO_KTASK_ASSIGN,在SwitchKtaskContext函数入口位置将C13管脚置为高电平,出口位置置为低电平;则C13管脚保持高电平的时间即切换时间。
# 编程代码清单
static BusType pin;
void RealtimeTaskSwitchTest()
{
struct PinParam test_pin;
struct PinStat test_pin_stat;
int ret = 0;
struct BusConfigureInfo configure_info;
struct BusBlockWriteParam write_param;
configure_info.configure_cmd = OPE_CFG;
configure_info.private_data = (void *)&test_pin;
write_param.buffer = (void *)&test_pin_stat;
/* config test pin as output*/
test_pin.cmd = GPIO_CONFIG_MODE;
test_pin.pin = GPIO_C13;
test_pin.mode = GPIO_CFG_OUTPUT;
ret = BusDrvConfigure(pin->owner_driver, &configure_info);
if (ret != EOK) {
KPrintf("config test_pin %d failed!\n", GPIO_C13);
return ;
}
/* set test pin as low*/
test_pin_stat.pin = GPIO_C13;
test_pin_stat.val = GPIO_LOW;
BusDevWriteData(pin->owner_haldev, &write_param);
while(1){
DelayKTask(1);
}
}
int TestRealtime(int argc, char * argv[])
{
int ret = 0;
struct BusConfigureInfo configure_info;
pin = BusFind(PIN_BUS_NAME);
if (!pin) {
KPrintf("find %s failed!\n", PIN_BUS_NAME);
return -ERROR;
}
pin->owner_driver = BusFindDriver(pin, PIN_DRIVER_NAME);
pin->owner_haldev = BusFindDevice(pin, PIN_DEVICE_NAME);
configure_info.configure_cmd = OPE_INT;
ret = BusDrvConfigure(pin->owner_driver, &configure_info);
if (ret != EOK) {
KPrintf("initialize %s failed!\n", PIN_BUS_NAME);
return -ERROR;
}
RealtimeTaskSwitchTest();
return 0;
}
因为测试单板为cortex-m4单板,该系列单板的线程切换是基于pendSV CPU异常进行线程切换,因此下面基于该特点区分测试场景:
- 测量pendSV异常切换,在SwitchKtaskContext函数入口处将C13管脚置为高电平,在pendSV异常处理过程,保存现场之后,切换到目标任务之前将C13管脚置为低电平。得出的管脚电平时间即为带pendSV异常的的任务切换时间。
- 只测了SwitchKtaskContext,在SwitchKtaskContext函数入口处将C13管脚置为高电平,在出口位置,将C13管脚置为低电平。得出的管脚电平时间即为不计算pendSV异常的的任务切换时间。
void __attribute__((naked)) HwInterruptcontextSwitch(x_ubase from, x_ubase to, struct TaskDescriptor *to_task, void *context)
{
/* 将GPIO C13置为高电平 */
asm volatile("LDR r2, =0x40020818"); // 测试代码
asm volatile("MOV r3, #0x2000"); // 测试代码
asm volatile("STR r3, [r2]"); // 测试代码
asm volatile ("LDR r4, =KtaskSwitchInterruptFlag");
asm volatile ("LDR r5, [r4]");
asm volatile ("CMP r5, #1");
asm volatile ("BEQ Arm32SwitchReswitch");
asm volatile ("MOV r5, #1");
asm volatile ("STR r5, [r4]");
asm volatile ("LDR r4, =InterruptFromKtask");
asm volatile ("STR r0, [r4]");
asm volatile ("B Arm32SwitchReswitch");
}
void __attribute__((naked)) Arm32SwitchReswitch()
{
asm volatile ("LDR r4, =InterruptToKtask");
asm volatile ("STR r1, [r4]");
asm volatile ("LDR r4, =InterruptToKtaskDescriptor");
asm volatile ("STR r2, [r4]");
asm volatile ("LDR r0, =" NVIC_INT_CTRL);
asm volatile ("LDR r1, =" NVIC_PENDSVSET);
asm volatile ("STR r1, [r0]");
/* 将GPIO C13置为低电平 */
asm volatile("LDR r2, =0x4002081a"); // 测试代码
asm volatile("MOV r3, #0x2000"); // 测试代码
asm volatile("STR r3, [r2]"); // 测试代码
asm volatile ("BX LR");
}
void __attribute__((naked)) SwitchKtaskContext(x_ubase from, x_ubase to, struct TaskDescriptor *to_task)
{
asm volatile("B HwInterruptcontextSwitch");
}
.global PendSV_Handler
.type PendSV_Handler, %function
PendSV_Handler:
MRS r2, PRIMASK
CPSID I
LDR r0, =KtaskSwitchInterruptFlag
LDR r1, [r0]
CBZ r1, pendsv_exit
MOV r1, #0x00
STR r1, [r0]
LDR r0, =InterruptFromKtask
LDR r1, [r0]
CBZ r1, switch_to_task
MRS r1, psp
STMFD r1!, {r4 - r11}
#if defined (__VFP_FP__) && !defined(__SOFTFP__)
MOV r4, #0x00
TST lr, #0x10
MOVEQ r4, #0x01
STMFD r1!, {r4}
#endif
LDR r0, [r0]
STR r1, [r0]
switch_to_task:
/* 将GPIO C13置为低电平 */
LDR r2, =0x4002081a // 测试代码
MOV r3, #0x2000 // 测试代码
STR r3, [r2] // 测试代码
# 示波器测试选项设置
- 通道设置
- 耦合:直流
- 带宽限制:关闭
- 伏/格:粗调
- 探头:10X 电压
- 反相:关闭
- 触发设置
- 类型:边沿
- 信源: CH1
- 斜率:上升
- 模式:自动
- 触发电压:略低于最高电平即可
- 测量设置
- 测量选通:开启
- 类型:时间
- 信源:CH1
- Scale:500ns
# 测试结果
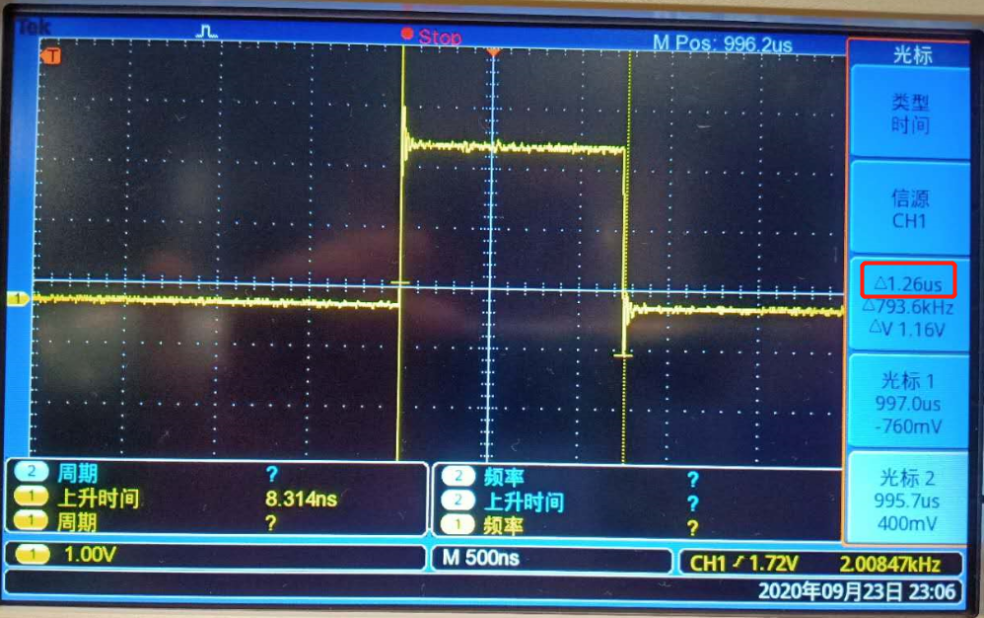
从示波器测试结果上来看,单独测试 SwitchKtaskContext 的执行时间是1.26us。
# 基于 RISC-V 处理器的任务切换性能测试
# 测试方法
为了测试系统的任务切换时间,考虑使用GPIO管脚进行测试,将GPIO在任务切换开始和结束时分别置为高电平和低电平。
- 配置GPIO18管脚为输出模式,接示波器通道1或2
- 示波器GND和开发板GND共地对接

XiUOS的任务切换函数为宏定义DO_KTASK_ASSIGN,在 SwitchKtaskContext 函数入口位置将 GPIO18 管脚置为高电平,出口位置SaveMpie置为低电平;则GPIO18管脚保持高电平的时间即切换时间。
# 编程代码清单
static BusType pin;
void RealtimeTaskSwitchTest()
{
struct PinParam test_pin;
struct PinStat test_pin_stat;
struct BusConfigureInfo configure_info;
struct BusBlockWriteParam write_param;
configure_info.configure_cmd = OPE_CFG;
configure_info.private_data = (void *)&test_pin;
write_param.buffer = (void *)&test_pin_stat;
test_pin.cmd = GPIO_CONFIG_MODE;
test_pin.pin = GPIO_18;
test_pin.mode = GPIO_CFG_OUTPUT;
BusDrvConfigure(pin->owner_driver, &configure_info);
test_pin_stat.pin = GPIO_18;
test_pin_stat.val = GPIO_LOW;
BusDevWriteData(pin->owner_haldev, &write_param);
while (1) {
DelayKTask(10);
}
}
int TestRealtime(int argc, char * argv[])
{
int ret = 0;
struct BusConfigureInfo configure_info;
pin = BusFind(PIN_BUS_NAME);
if (!pin) {
KPrintf("find %s failed!\n", PIN_BUS_NAME);
return -ERROR;
}
pin->owner_driver = BusFindDriver(pin, PIN_DRIVER_NAME);
pin->owner_haldev = BusFindDevice(pin, PIN_DEVICE_NAME);
configure_info.configure_cmd = OPE_INT;
ret = BusDrvConfigure(pin->owner_driver, &configure_info);
if (ret != EOK) {
KPrintf("initialize %s failed!\n", PIN_BUS_NAME);
return -ERROR;
}
RealtimeTaskSwitchTest();
return 0;
}
初始化GPIO18为输出模式,并初始化为低电平;在while(1)当中调用delay函数,每隔1个时间片发生一次调度。在下面的switch函数入口和出口位置操作GPIO。
void __attribute__((naked)) SwitchKtaskContext(x_ubase from, x_ubase to, struct TaskDescriptor *to_task)
{
/* 将 GPIO18 置为高电平 */
asm volatile ("lui a5, 0x38001"); // 测试代码
asm volatile ("addi a5, a5, 12"); // 测试代码
asm volatile ("lw a5, 0(a5)"); // 测试代码
asm volatile ("sext.w a4, a5"); // 测试代码
asm volatile ("lui a5, 0x38001"); // 测试代码
asm volatile ("addi a5, a5, 12"); // 测试代码
asm volatile ("ori a4, a4, 5"); // 测试代码
asm volatile ("sext.w a4, a4"); // 测试代码
asm volatile ("sw a4, 0(a5)"); // 测试代码
asm volatile ("addi sp, sp, -32 * " RegLengthS);
asm volatile (StoreDS " sp, (a0)");
asm volatile (StoreDS " x1, 0 * " RegLengthS "(sp)");
asm volatile (StoreDS " x1, 1 * " RegLengthS "(sp)");
asm volatile ("csrr a0, mstatus");
#ifndef TASK_ISOLATION
asm volatile ("andi a0, a0, 8");
asm volatile ("beqz a0, SaveMpie");
asm volatile ("li a0, 0x80");
#endif
asm volatile ("j SaveMpie");
}
void __attribute__((naked)) SaveMpie()
{
asm volatile (StoreDS " a0, 2 * " RegLengthS "(sp)");
asm volatile (StoreDS " tp, 4 * " RegLengthS "(sp)");
asm volatile (StoreDS " t0, 5 * " RegLengthS "(sp)");
asm volatile (StoreDS " t1, 6 * " RegLengthS "(sp)");
asm volatile (StoreDS " t2, 7 * " RegLengthS "(sp)");
asm volatile (StoreDS " s0, 8 * " RegLengthS "(sp)");
asm volatile (StoreDS " s1, 9 * " RegLengthS "(sp)");
asm volatile (StoreDS " a0, 10 * " RegLengthS "(sp)");
asm volatile (StoreDS " a1, 11 * " RegLengthS "(sp)");
asm volatile (StoreDS " a2, 12 * " RegLengthS "(sp)");
asm volatile (StoreDS " a3, 13 * " RegLengthS "(sp)");
asm volatile (StoreDS " a4, 14 * " RegLengthS "(sp)");
asm volatile (StoreDS " a5, 15 * " RegLengthS "(sp)");
asm volatile (StoreDS " a6, 16 * " RegLengthS "(sp)");
asm volatile (StoreDS " a7, 17 * " RegLengthS "(sp)");
asm volatile (StoreDS " s2, 18 * " RegLengthS "(sp)");
asm volatile (StoreDS " s3, 19 * " RegLengthS "(sp)");
asm volatile (StoreDS " s4, 20 * " RegLengthS "(sp)");
asm volatile (StoreDS " s5, 21 * " RegLengthS "(sp)");
asm volatile (StoreDS " s6, 22 * " RegLengthS "(sp)");
asm volatile (StoreDS " s7, 23 * " RegLengthS "(sp)");
asm volatile (StoreDS " s8, 24 * " RegLengthS "(sp)");
asm volatile (StoreDS " s9, 25 * " RegLengthS "(sp)");
asm volatile (StoreDS " s10, 26 * " RegLengthS "(sp)");
asm volatile (StoreDS " s11, 27 * " RegLengthS "(sp)");
asm volatile (StoreDS " t3, 28 * " RegLengthS "(sp)");
asm volatile (StoreDS " t4, 29 * " RegLengthS "(sp)");
asm volatile (StoreDS " t5, 30 * " RegLengthS "(sp)");
asm volatile (StoreDS " t6, 31 * " RegLengthS "(sp)");
asm volatile (LoadDS " sp, (a1)");
asm volatile ("mv a0, a2");
asm volatile ("jal RestoreCpusLockStatus");
/* 将GPIO18 置为低电平 */
asm volatile ("lui a5, 0x38001"); // 测试代码
asm volatile ("addi a5, a5, 12"); // 测试代码
asm volatile ("lw a5, 0(a5)"); // 测试代码
asm volatile ("sext.w a4, a5"); // 测试代码
asm volatile ("lui a5, 0x38001"); // 测试代码
asm volatile ("addi a5, a5, 12"); // 测试代码
asm volatile ("addi a4, a4, -6"); // 测试代码
asm volatile ("sext.w a4, a4"); // 测试代码
asm volatile ("sw a4, 0(a5)"); // 测试代码
asm volatile ("j SwitchKTaskContextExit");
}
# 示波器测试选项设置
- 通道设置
- 耦合:直流
- 带宽限制:关闭
- 伏/格:粗调
- 探头:10X 电压
- 反相:关闭
- 触发设置
- 类型:边沿
- 信源: CH1
- 斜率:上升
- 模式:自动
- 触发电压:略低于最高电平即可
- 测量设置
- 测量选通:开启
- 类型:时间
- 信源:CH1
- Scale:250ns
# 测试结果
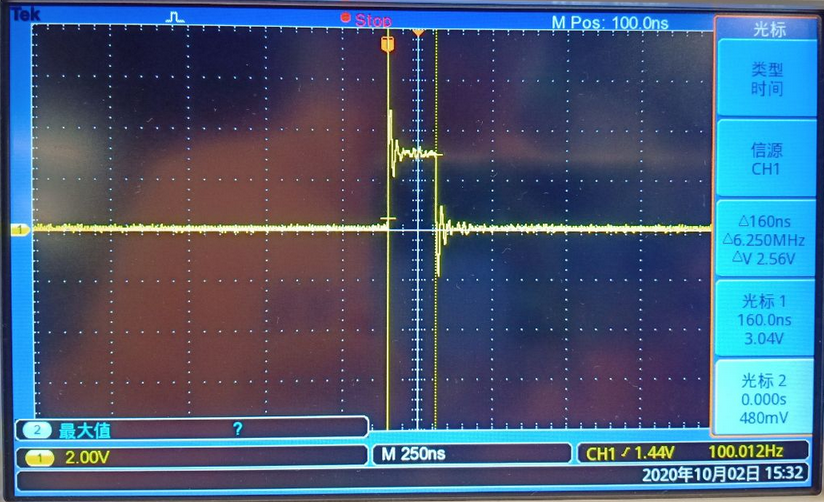
从示波器测试结果上来看,测试 SwitchKtaskContext 的执行时间是160ns。
# 任务切换性能测试对比
对sylixos的中断响应性能测试结果,如下:
| 操作系统 | 测试开发板 | CPU | 任务切换时间(ns) |
|---|---|---|---|
| sylixos | mini210s开发板 | ARM Cortex-A8 主频 1GHz | 577.1 |
| XiUOS | KD233开发板 | RISC-V K210 主频 400MHz | 160 |
| XiUOS | STM32F407G-DISC1开发板 | STM32f407 主频 168MHz | 1260 |
结果分析:
- XiUOS 在RISC-V K210 400MHz CPU主频上任务切换时间为 160 ns 低于 sylixos 的 577.1 ns
- 若进行同等1 GHz 主频换算,K210 上的任务切换时间应为 62.5 ns,XiUOS 的任务切换的效率比 sylixos 提高 8.2倍
- 在ARM stm32f407 168MHz CPU主频任务切换时间 1260 ns高于1GHz主频测试的sylixos
- 若进行同等1 GHz 主频换算,STM32F407 上的任务切换时间应为 206.718 ns,XiUOS 的任务切换的效率比 sylixos 提高 1.8倍
由于XiUOS优化了任务切换的流程,减少了执行指令数,因此,同等主频条件下,任务切换时间更短。
# 使用场景
- 在多处理器设备上,多个任务可以并行运行,从而提高处理器的利用率。
- 在一些中断驱动的应用中,如果中断需要处理的工作过于复杂,则可以创建一个任务专门用于处理相关工作,从而改善中断延迟。