# 知 - 智能框架
# 基本框架
传统嵌入式场景下,节点端主要负责数据采集和简单处理,复杂的任务放在边缘或者云端完成。而随着嵌入式芯片性能越来越强,在端侧承担更多的计算也成了目前的一个趋势,比如 ST 推出的针对 STM 平台的神经网络加速库 STM32 Cube.AI。最近,部分厂商开始在嵌入式平台上引入神经网络加速模块,比如 ARM 即将发布的针对嵌入式场景的 Ethos-U55 神经网络处理器,以及 勘智 K210 平台嵌入了一颗卷积网络加速器 KPU,使得端侧算力进一步增强,从而使我们可以在端侧做更多的计算和任务,从而相比传统解决方案有更好的延时、更低的成本。
我们提供了端侧的智能框架,将部分 AI 计算下沉到端侧,可以在端侧完成部分 AI 计算,从而为工业场景下的图像、声音等数据采集和感知提供更丰富的解决方案。比如,对于工业环境下的机械仪表读数识别,我们在初始化时通过边缘或者云端完成仪表数字分析,后续运行中我们在节点端完成仪表指针识别并计算仪表读数,从而在运行中不需要和边缘或者云端通信就可以完成读数识别,提供了更低的延时。
端侧智能框架基本结构如下:
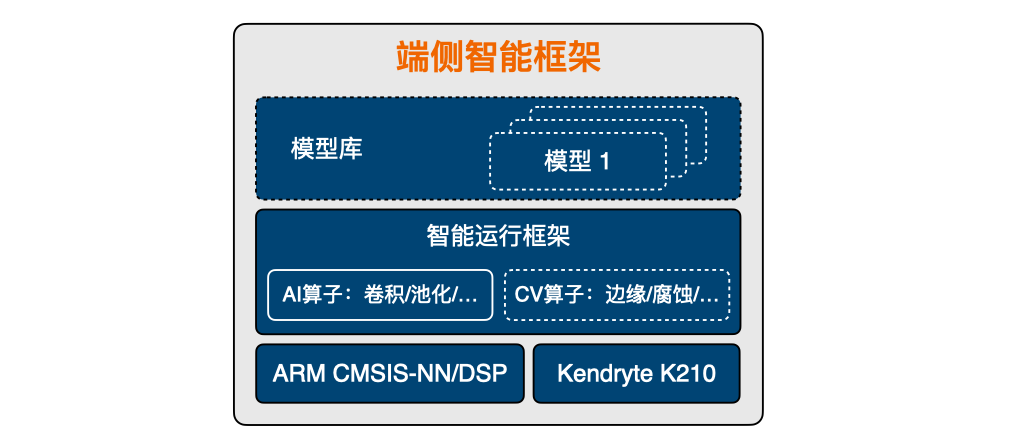
图中 端侧智能框架 是我们提供的在节点端进行智能计算的框架,能够提供在端侧进行初步的智能运算。
端侧智能框架 目前在 STM32/RISC-V 平台上支持 TensorFlow Lite for Microcontroller,CV算子目前暂不支持。后续工作中,我们尝试对AI算子进行优化加速并提供部分 CV 支持。
# 端侧 Framework 的使用说明
端侧智能框架 的具体 API 后续放出,目前可以参照 TF Lite for MCU 官方教程 (opens new window) ,详细说明后续补充。
针对 TF Lite for MCU 的使用,可以参考 XiUOS 代码中的 applications 下面的 tflite_mnist、tflite_sin 应用。